

URL 是 Uniform Resource Locator 的缩写,即统一资源定位符。URL 就是一个给定的独特资源在 Web 上的地址。如果你从事 Web 前端开发有一段时间了,相信一定会遇到需要使用 JavaScript 解析 URL 地址信息的时候。本文就介绍一下如何使用 JavaScript 解析 URL。文章源自灵鲨社区-https://www.0s52.com/bcjc/javascriptjc/16619.html
URL 格式
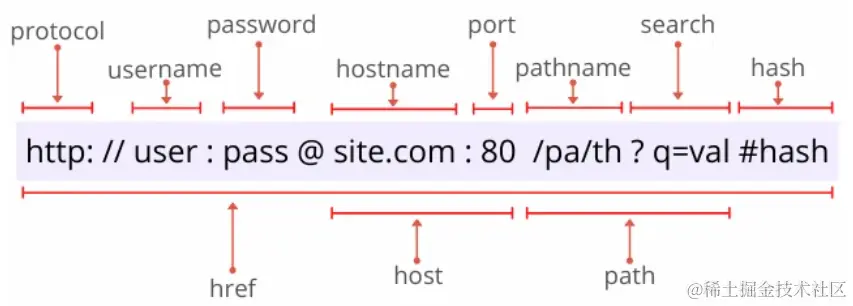
让我们再来回顾一下 URL 的格式:文章源自灵鲨社区-https://www.0s52.com/bcjc/javascriptjc/16619.html
 文章源自灵鲨社区-https://www.0s52.com/bcjc/javascriptjc/16619.html
文章源自灵鲨社区-https://www.0s52.com/bcjc/javascriptjc/16619.html
完整的 URL 信息包括以下几点:文章源自灵鲨社区-https://www.0s52.com/bcjc/javascriptjc/16619.html
- 协议(protocol):采用的协议方案;
- 登录信息(username & password):(可选项)指定用户名和密码,用来从服务器获取资源时的认证信息;
- 服务器地址(hostname):待访问的服务器地址。可以是域名形式也可以是 IP 地址;
- 服务器端口号(port):;(可选项)指定服务器连接网路的端口号;
- 带层次的文件路径(pathname):指定服务器上的文件路径来定位特指的资源;
- 查询字符串(search):(可选项)查询字符串参数;
- 片段标识符(hash):(可选项)用来标记已获取资源中的子资源;
解析 URL
在回顾 URL 都包括哪些信息后,接下来就介绍如何使用 JavaScript 来解析 URL 的这些信息。以本文地址为例:文章源自灵鲨社区-https://www.0s52.com/bcjc/javascriptjc/16619.html
vbnet
http://www.yaohaixiao.com/blog/how-to-parse-url-with-javascript/
按照 URL 的格式规范,本文的 URL 地址解析后的信息应该如下:文章源自灵鲨社区-https://www.0s52.com/bcjc/javascriptjc/16619.html
- protocol: http
- hostname: www.yaohaixiao.com
- pathname: /blog/how-to-parse-url-with-javascript/
可以看到,本文地址的 URL 解析后的信息并没有前文提到的完整 URL 信息中那么多。这是因为 URL 信息中有几项信息是可选项信息,本文的示例 URL 地址中都是没有值的。文章源自灵鲨社区-https://www.0s52.com/bcjc/javascriptjc/16619.html
在通过人工分析的方式分析了一遍,现在就要开始使用 JavaScript 编程解析 URL 信息了。当然,解析 URL 信息的方法很多,本文主要介绍两种解析方法:正则表达式解析 和 URL 构造函数解析。文章源自灵鲨社区-https://www.0s52.com/bcjc/javascriptjc/16619.html
正则表达式解析
使用 JavaScript 中的正则表达解析 URL 信息应该最常见的方法了,当然这需要具备一定的 JavaScript 正则表达式相关的知识。而使用正则表达式分析 URL 地址其实也并不复杂。文章源自灵鲨社区-https://www.0s52.com/bcjc/javascriptjc/16619.html
按照前文图片中的 URL 信息的结构,使用括号“()”分组表达符对 URL 中对应的信息进行分组,正则表达式的伪代码大致如下:文章源自灵鲨社区-https://www.0s52.com/bcjc/javascriptjc/16619.html
ruby
/^((protocol):)?//((username):(password)@)?(hostname)(:(port))?(pathname)(?(search))?(#(hash))?/
可以看到,正则表达式也分了 7 组:
- protocol - 协议分组:((protocol):)?,最外层的 ()? 中,? 表示数量为 0 或 1 个,即表示协议名称是可选的;
- auth - 授权信息分组:((username):(password)@)?,与协议分组一样,整个授权分组也是可选的。其中又包含 username 子分组和 password 子分组;
- hostname - 服务器地址分组:(hostname),表示 hostname 信息是必选的;
- port - 端口分组:(:(port))?,表示端口号是可选的;
- pathname - 带层次的文件路径分组:(pathname),表示文件路径是必选的;
- search - 查询字符串分组:(?(search))?,表示查询字符串是可选的;
- hash - 片段标识符分组:(#(hash))?,表示片段标识符分组也是可选的;
完成了大的分组后,接下来要处理的问题就是相对比较容易了,就是用真是的正则表达式将使用英文字母的伪代码内容替换掉。对应完整的 JavaScript 的正则表达式代码如下图:
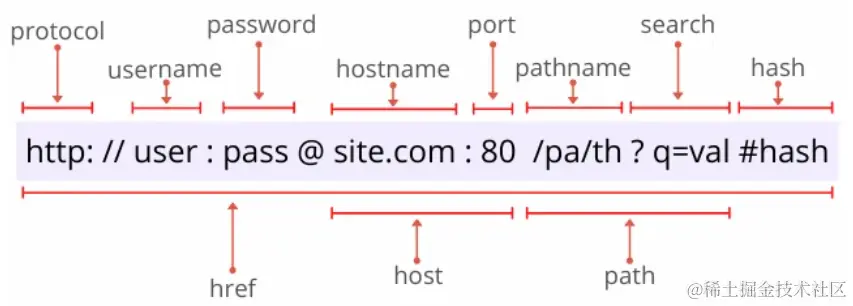
可以看到,途中蓝色文字标识的是伪代码中对应的 7 个分组,而灰色文字标识的是最终需要获取的 URL 对应的信息。下面就详细介绍一下各个分组的正则表达式的含义。
1. protocol(协议分组)
csharp
// ((protocol):)? (([^:/?#]+):)?
([^:/?#]+),匹配协议名称(子分组),具体的含义如下:
- [^],表示除了“^”符号后的字符以外的所有字符。 [^:/?#] 就表示除了":"(冒号)、"/"(反斜杠)、“?”(问号)和“#”(井号)以外的所有字符。也就是是说,协议名称可是除了以上符号以外的所有字符都可以。我这个匹配比较宽泛,通常协议名称是字母,所以也可以写作([a-zA-Z])。除非确定邀请非常高的匹配精度,可以适当写宽泛一些。
- []+,中括号后的 + 表示数量为 1~n 个,所以 ([^:/?#]+) 整个的意思是协议名称匹配为除了":"(冒号)、“?”(问号)和“#”(井号)以外的所有字符字符都可以,并且长度要求是1个以上。
(([^:/?#]+):)?,匹配协议名称加“:”格式,例如:http: 。当然,在介绍分组伪代码的时候,介绍过了,()? 括号后的 ? 标识整个协议分组是可选的。而之所以将协议分组作为可选的,是应为实际的应用中:
arduino
//www.yaohaixiao.com/favicon.ico
这种不带协议名称的 URL 地址也是允许的。
因此,(([^:/?#]+):)? 这段表达式将匹配 2 组数据:http: 和 http,前者是大分组 ()? 匹配的信息,后者则是子分组 ([^:/?#]+) 匹配的信息,也是真正希望解析的 URL 协议信息。不过由于整个协议分组是可选的,因此协议分组的两个分组也可能都匹配不到数据。
2. auth(授权信息分组)
csharp
// ((username):(password)@)? (([^/?#]+):(.+)@)?
([^/?#]+),匹配用户名,由于规则和匹配协议名称一样,在此就不重复了。
(.+),匹配密码。具体含义如下:
- “.”,表示任何字符。因为密码由于考虑安全因数,一般都希望密码是包含字符(而且包含大小写),数组和特殊字符的组合。所以直接不做任何限制,允许密码包含任意字符。
- “+”,表示数量为1个或者多个,即密码不能为空。
(([^/?#]+):(.+)@)?,匹配完整的授权信息。匹配的数据如:yao:Yao1!@。与授权信息一样,最外层的()?表示授权信息也是可选的。
因此,(([^/?#]+):(.+)@)? 整个会匹配 3 组数据:完整的用户授权分组信息、用户名以及密码。由于整个协议分组是可选的,因此授权分组的 3 组信息也可能都匹配不到数据。
3. hostname(服务器地址分组)
csharp
// (hostname) ([^/?#:]*)
([^/?#:]*),匹配服务器地址信息。和协议分组的表达式一样,使用了比较宽松的匹配逻辑。
4. port(端口分组)
scss
// (:(port))? (:(d+))?
(d+),匹配端口号信息。端口号只能是数字类型的数据,对端口号长度的要求是至少有一个。对端口号的长途匹配也没有使用太严苛的长度要求。虽然通常端口号的长度一般是 2 位数字起,但还是建议遵循之前提到的建议,如果不是有具体的精度要求,表达式都可以使用宽泛一些的匹配规则。
(:(d+))?,匹配完整的端口号分组信息。匹配的格式如:“:80”。
同样的,整个端口号分组匹配的表达式也是可以匹配 2 组数据::80 和 80。当然,端口号分组也是可选的,很大可能配备不到信息。
5. pathname(带层次的文件路径分组)
csharp
// (pathname) ([^?#]*)
([^?#]*),匹配带层次的文件路径信息。具体的含义是:
- [^?#],除了“?”(问号)和“#”(井号)以外的所有字符都可以作为路径信息。
- []*,表示字符长度可以是任意长度。因为 URL 地址可以是这样的:
arduino
http://www.yaohaixiao.com。
虽然没有使用“()?”的形式表示路径为可选的,但用于路径的长度可以为 0,其实路径也是可选的,也有可能匹配不到数据。
6. search(查询字符串分组)
csharp
// (?(search))? (?([^#]*))?
([^#]),匹配查询字符串信息。除了“#”(井号)以外的所有字符都可以作为查询字符串信息。[] 表示可选,因为路径:www.yaohxiao.com? 也是允许的。
(?([^#]*))?,匹配查询字符串的分组信息。匹配的格式如:?id=23。当然也是可选的。
整个查询字符串分组的表达式(?([^#]*))? ,也是可以匹配出 2 组数据。而因为整个分组是可选的,所以查询字符串的分组匹配也很可能匹配不到数据。
7. hash(片段标识符分组)
bash
// (#(hash))? (#(.*))?
(.),匹配片段标识。“.”表示任意字符,“”表示任意长度。即片段表示可以是任意字符,且长度为任意长度的。
(#(.*))?,匹配判断标识分组。匹配的格式如:#1234。看到()?,就知道片段标识符分组是可选的。
整个片段标识符分组的表达式(#(.*))? ,也可以匹配出 2 组数据。当然,也可能什么也匹配不上。
介绍完所有的分组表达式,最后来统计一下最多一共可以匹配多少组数据:2 + 3 + 1 + 2 + 1 + 2 + 2 + 1 = 14。其中,最后一个加1,是匹配的整个 URL 地址。
验证一下使用正则表达式对本文 URL 地址的匹配信息:
js
const URL = 'http://www.yaohaixiao.com/blog/how-to-parse-url-with-javascript/'const pattern = /^(([^:/?#]+):)?//(([^/?#]+):(.+)@)?([^/?#:]*)(:(d+))?([^?#]*)(?([^#]*))?(#(.*))?/const matches = URL.match(pattern)console.log(matches)
输出的结果为:
makefile
0: "http://www.yaohaixiao.com/blog/how-to-parse-url-with-javascript/" 1: "http:" 2: "http" 3: undefined 4: undefined 5: undefined 6: "www.yaohaixiao.com" 7: undefined 8: undefined 9: "/blog/how-to-parse-url-with-javascript/" 10: undefined 11: undefined 12: undefined 13: undefined groups: undefined index: 0 input: "http://www.yaohaixiao.com/blog/how-to-parse-url-with-javascript/"
正如之前人工分析的一样,使用 match() 方法匹配了 14 个结果。由于示例 URL 地址中很多可选的信息都是没有的,所以匹配结果为 undefined。但这个结果并不是那么一目了然,让我们看看完整的 parseURL() 方法。
完整的 parseURL() 方法
完整的 parseURL() 方法的如下:
js
/** * 分析 url 地址,将解析的结果作为对象返回,返回属性有: * 1. href - 完整 URL 地址 * 2. protocol - 协议 * 3. username - 用户名 * 4. password - 密码 * 5. host - 域名地址 * 6. hostname - 域名名称 * 7. port - 端口号 * 8. path - 路径 * 9. pathname - 路径名 * 10. search - 查询参数 * 11. hash - 哈希值 * ==================================================== * @param {String} url - URL地址 * @returns {Object} */const parseURL = (url) => { const pattern = /^(([^:/?#]+):)?//(([^/?#]+):(.+)@)?([^/?#:]*)(:(d+))?([^?#]*)(?([^#]*))?(#(.*))?/ const matches = url.match(pattern) return { href: url, origin: matches[1] + matches[2], protocol: matches[2] || '', username: matches[4] || '', password: matches[5] || '', host: matches[6] + (matches[7] ? matches[7] : ''), hostname: matches[6], port: matches[8] || '', path: matches[9] + matches[10], pathname: matches[11], search: matches[10] || '', hash: matches[13] || '' }}
它返回一个对象,将正则表达式匹配的信息复制给具体的 URL 名称的属性。看看使用 parseURL() 方法解析前面的 URL 地址的结果吧:
js
const URL = 'http://www.yaohaixiao.com/blog/how-to-parse-url-with-javascript/' const result = parseURL(URL)
解析后的结果:
json
{ hash: undefined, host: "www.yaohaixiao.com", hostname: "www.yaohaixiao.com", href: "http://www.yaohaixiao.com/blog/how-to-parse-url-with-javascript/", orgin: "http://www.yaohaixiao.com", password: undefined, path: "/blog/how-to-parse-url-with-javascript/undefined", pathname: undefined, port: undefined, protocol: "http", search: undefined, username: undefined,}
现在解析后的结果是不是一目了然了?
URL 构造函数解析
除了前文介绍的使用 JavaScript 中的正则表达式解析 URL 信息之外,还可以利用新的 URL 构造函数来解析 URL 地址,并且解析起来更加简单。
URL() 构造函数
URL() 构造函数返回一个新创建的 URL 对象,表示由一组参数定义的 URL。如果给定的基本 URL 或生成的 URL 不是有效的 URL 链接,则会抛出一个 TypeError。
语法如下:
js
new URL(url [, base]);
- url:是一个表示绝对或相对 URL 的 DOMString。如果url 是相对 URL,则会将 base 用作基准 URL。如果 url 是绝对URL,则无论参数base是否存在,都将被忽略;
- base:可选,是一个表示基准 URL 的 DOMString,在 url 是相对 URL 时,它才会起效。如果未指定,则默认为 '';
调用方法如下:
js
// 直接使用绝对 URL 地址方式调用 const url = new URL('http://example.com/path/index.html'); // 使用 path 加 base 地址参数的方式调用 const url = new URL('/path/index.html', 'http://example.com');
URL() 构造函数的接口信息如下:
js
interface URL { href: USVString; protocol: USVString; username: USVString; password: USVString; host: USVString; hostname: USVString; port: USVString; pathname: USVString; search: USVString; hash: USVString; // 只有 orgin 和 searchParams 是只读,其余的属性都是可修改的 readonly origin: USVString; readonly searchParams: URLSearchParams; toJSON(): USVString;}
所以每个使用 URL() 构造函数创建的实例,都会返回完整 URL 信息了。例如:
js
const url = new URL('http://www.yaohaixiao.com/blog/how-to-parse-url-with-javascript/');
返回的数据为:
json
{ hash: "", host: "www.yaohaixiao.com", hostname: "www.yaohaixiao.com", href: "http://www.yaohaixiao.com/blog/how-to-parse-url-with-javascript/", origin: "http://www.yaohaixiao.com", password: "", pathname: "/blog/how-to-parse-url-with-javascript/", port: "", protocol: "http:", search: "", searchParams: URLSearchParams {}, username: ""}
可以看到,使用 URL() 构造函数返回的数据和前文使用正则表达式解析的数据基本一致,只是这里多了一个 searchParams 对象。
可以看到,使用 URL() 构造函数返回的数据和前文使用正则表达式解析的数据基本一致,只是这里多了一个 searchParams 对象。
searchParams 对象又是 URLSearchParams 对象的一个实例,用来获取查询字符串中的某个参数的值,用法如下:
js
const url = new URL('http://www.yaohaixiao.com/blog/how-to-parse-url-with-javascript/?id=312'); url.searchParams.get('id') // -> 123
URL() 构造函数的功能是不是很强大了。不知道 URL() 构造函数浏览器支持的情况怎么样?
URL() 构造函数的浏览器兼容情况
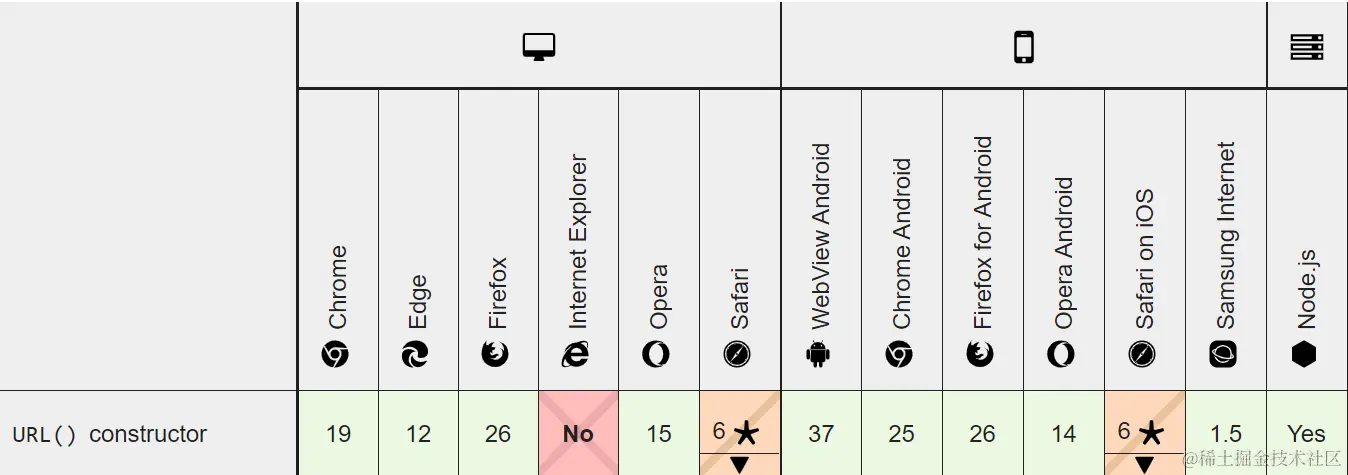
在主流浏览器中,除了 IE 浏览器,其余的都基本支持了。基本上可以放心使用 URL() 构造函数来解析 URL 信息。
正则表达式解析 VS URL 构造函数解析
对两种解析 URL 信息的方法进行比较,很明显使用 URL() 构造函数解析的方法操作更加简单,并且提供更多的功能。但与正则表达式解析方法比较,可能唯一不足的就是在浏览器兼容性方面稍差。
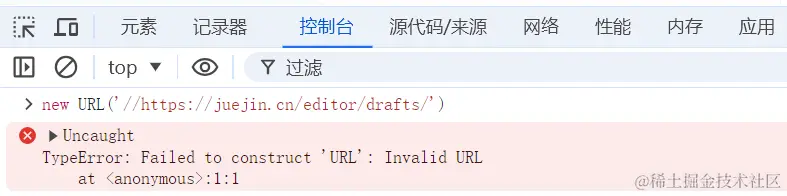
不过 URL() 有个问题是需要注意的,就是 URL 字符串的格式不是正确的格式的时候会报错。例如前文提到的这种 URL 地址:
arduino
new URL('//https://juejin.cn/editor/drafts/')
其实,只要稍微调整一下,就可以将两种方法结合起来,在支持 URL() 构造函数的浏览器中使用构造函数,不知支持的时候则使用正则表达式解析:
js
/** * 分析 url 地址,将解析的结果作为对象返回,返回属性有: * 1. href - 完整 URL 地址 * 2. orgin - 网站首页地址 * 3. protocol - 协议 * 4. username - 用户名 * 5. password - 密码 * 6. host - 域名地址 * 7. hostname - 域名名称 * 8. port - 端口号 * 9. path - 路径 * 10. pathname - 路径名 * 11. search - 查询参数 * 12. hash - 哈希值 * ==================================================== * @param {String} url - URL地址 * @returns {Object} */ function parseURL (url) { var pattern = /^(([^:/?#]+):)?//(([^/?#]+):(.+)@)?([^/?#:]*)(:(d+))?([^?#]*)(?([^#]*))?(#(.*))?/ var matches = url.match(pattern) try { // 支持 URL() 构造函数,且可以正确转义 URL 字符串 return new URL(url) } catch(e) { // 否则使用正则表达式解析 return { href: url, origin: matches[1] + matches[2], protocol: matches[2] || '', username: matches[4] || '', password: matches[5] || '', host: matches[6] + (matches[7] ? matches[7] : ''), hostname: matches[6], port: matches[8] || '', path: matches[9] + matches[10], pathname: matches[11], search: matches[10] || '', hash: matches[13] || '' } } }
评论