

本文分享自华为云社区《MySQL全文索引源码剖析之Insert语句执行过程》,作者:GaussDB 数据库。文章源自灵鲨社区-https://www.0s52.com/bcjc/mysqljc/16126.html
本文主要介绍MySQL 8.0数据字典的基本概念和数据字典的初始化与启动加载的主要流程。文章源自灵鲨社区-https://www.0s52.com/bcjc/mysqljc/16126.html
MySQL 8.0数据字典简介
数据字典(Data Dictionary, DD)用来存储数据库内部对象的信息,这些信息也被称为元数据(Metadata),包括schema名称、表结构、存储过程的定义等。文章源自灵鲨社区-https://www.0s52.com/bcjc/mysqljc/16126.html
 文章源自灵鲨社区-https://www.0s52.com/bcjc/mysqljc/16126.html
文章源自灵鲨社区-https://www.0s52.com/bcjc/mysqljc/16126.html
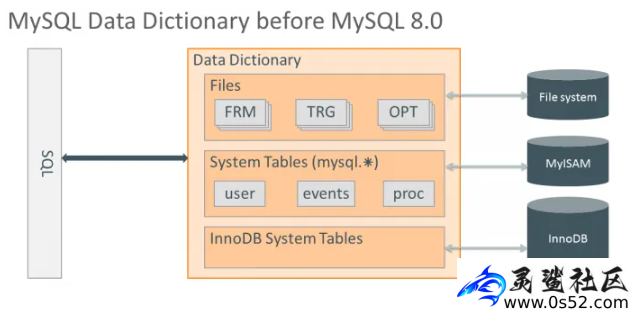
图1 MySQL 8.0之前的数据字典文章源自灵鲨社区-https://www.0s52.com/bcjc/mysqljc/16126.html
图片来源:MySQL 8.0 Data Dictionary: Background and Motivation文章源自灵鲨社区-https://www.0s52.com/bcjc/mysqljc/16126.html
如图1所示,MySQL 8.0之前的元数据,分散存储在许多不同的位置,包括各种元数据文件,不支持事务的表和存储引擎特有的数据字典等;Server层和存储引擎层有各自的数据字典,其中一部分是重复的。文章源自灵鲨社区-https://www.0s52.com/bcjc/mysqljc/16126.html
以上的设计导致支持原子的DDL变得很困难,因此MySQL 8.0之前,如果DDL过程中发生crash,后期的恢复很容易出现各种问题,导致表无法访问、复制异常等。文章源自灵鲨社区-https://www.0s52.com/bcjc/mysqljc/16126.html
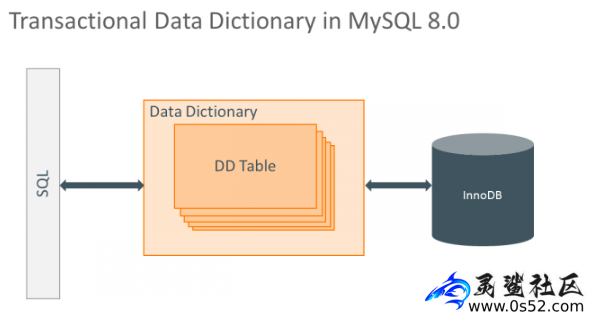
如图2所示,MySQL 8.0使用支持事务的InnoDB存储引擎作来存储元数据,实现数据字典的统一管理。这个改进消除了元数据存储的冗余,通过支持原子DDL,实现了DDL的crash safe。文章源自灵鲨社区-https://www.0s52.com/bcjc/mysqljc/16126.html
 文章源自灵鲨社区-https://www.0s52.com/bcjc/mysqljc/16126.html
文章源自灵鲨社区-https://www.0s52.com/bcjc/mysqljc/16126.html
图2 MySQL 8.0数据字典
图片来源:MySQL 8.0: Data Dictionary Architecture and Design
数据字典表都是隐藏的,只有在debug编译模式下,可以通过设置开关set debug='+d,skip_dd_table_access_check'来直接查看数据字典表。
css
mysql> set debug='+d,skip_dd_table_access_check';
Query OK, 0 rows affected (0.01 sec)
mysql> SELECT name, schema_id, hidden, type FROM mysql.tables where schema_id=1 AND hidden='System';
+------------------------------+-----------+--------+------------+
| name | schema_id | hidden | type |
+------------------------------+-----------+--------+------------+
| catalogs | 1 | System | BASE TABLE |
| character_sets | 1 | System | BASE TABLE |
| check_constraints | 1 | System | BASE TABLE |
| collations | 1 | System | BASE TABLE |
| column_statistics | 1 | System | BASE TABLE |
| column_type_elements | 1 | System | BASE TABLE |
| columns | 1 | System | BASE TABLE |
| dd_properties | 1 | System | BASE TABLE |
| events | 1 | System | BASE TABLE |
| foreign_key_column_usage | 1 | System | BASE TABLE |
| foreign_keys | 1 | System | BASE TABLE |
| index_column_usage | 1 | System | BASE TABLE |
| index_partitions | 1 | System | BASE TABLE |
| index_stats | 1 | System | BASE TABLE |
| indexes | 1 | System | BASE TABLE |
| innodb_ddl_log | 1 | System | BASE TABLE |
| innodb_dynamic_metadata | 1 | System | BASE TABLE |
| parameter_type_elements | 1 | System | BASE TABLE |
| parameters | 1 | System | BASE TABLE |
| resource_groups | 1 | System | BASE TABLE |
| routines | 1 | System | BASE TABLE |
| schemata | 1 | System | BASE TABLE |
| st_spatial_reference_systems | 1 | System | BASE TABLE |
| table_partition_values | 1 | System | BASE TABLE |
| table_partitions | 1 | System | BASE TABLE |
| table_stats | 1 | System | BASE TABLE |
| tables | 1 | System | BASE TABLE |
| tablespace_files | 1 | System | BASE TABLE |
| tablespaces | 1 | System | BASE TABLE |
| triggers | 1 | System | BASE TABLE |
| view_routine_usage | 1 | System | BASE TABLE |
| view_table_usage | 1 | System | BASE TABLE |
+------------------------------+-----------+--------+------------+
32 rows in set (0.01 sec)
上面查询得到的表就是隐藏的数据字典表,MySQL的元数据存储在这些表中。
在release编译模式下,如果要查看数据字典信息,只能通过INFORMATION_SCHEMA中的视图来查询。例如,可以通过视图information_schema.tables查询数据字典表mysql.tables。
sql
mysql> select TABLE_SCHEMA,TABLE_NAME,TABLE_TYPE,ENGINE
-> from information_schema.tables
-> where TABLE_SCHEMA = 'sbtest' limit 1;
+--------------+------------+------------+--------+
| TABLE_SCHEMA | TABLE_NAME | TABLE_TYPE | ENGINE |
+--------------+------------+------------+--------+
| sbtest | sbtest1 | BASE TABLE | InnoDB |
+--------------+------------+------------+--------+
1 row in set (0.00 sec)
数据字典表的相关代码
数据字典的代码位于sql/dd目录,所有数据字典相关的信息都在dd这个命名空间中,各数据字典表本身的定义位于sql/dd/impl/tables目录的代码中,可以理解为数据字典表的元数据在代码中已经定义好了。
以存储schema信息的schemata表为例,其类的声明如下:
csharp
class Schemata : public Entity_object_table_impl {
public:
// ...
// 所包含的字段 enum enum_fields {
FIELD_ID,
FIELD_CATALOG_ID,
FIELD_NAME,
FIELD_DEFAULT_COLLATION_ID,
FIELD_CREATED,
FIELD_LAST_ALTERED,
FIELD_OPTIONS,
FIELD_DEFAULT_ENCRYPTION,
FIELD_SE_PRIVATE_DATA,
NUMBER_OF_FIELDS // Always keep this entry at the end of the enum };
// 所包含的索引
enum enum_indexes {
INDEX_PK_ID = static_cast<uint>(Common_index::PK_ID),
INDEX_UK_CATALOG_ID_NAME = static_cast<uint>(Common_index::UK_NAME),
INDEX_K_DEFAULT_COLLATION_ID
};
// 所包含的外键
enum enum_foreign_keys { FK_CATALOG_ID, FK_DEFAULT_COLLATION_ID };
// ...
};
其构造函数定义了该表的名称、各字段、索引和外键等信息,以及该表默认存储的数据信息,如下所示:
arduino
Schemata::Schemata() {
// 表名 m_target_def.set_table_name("schemata");
// 字段定义
m_target_def.add_field(FIELD_ID, "FIELD_ID",
"id BIGINT UNSIGNED NOT NULL AUTO_INCREMENT");
// ...
// 索引定义
m_target_def.add_index(INDEX_PK_ID, "INDEX_PK_ID", "PRIMARY KEY (id)");
// ...
// 外键定义
m_target_def.add_foreign_key(FK_CATALOG_ID, "FK_CATALOG_ID",
"FOREIGN KEY (catalog_id) REFERENCES
catalogs(id)");
// ...
// 初始化时额外需要执行的DML语句
m_target_def.add_populate_statement(
"INSERT INTO schemata (catalog_id, name, default_collation_id, created, "
"last_altered, options, default_encryption, se_private_data) VALUES "
"(1,'information_schema',33, CURRENT_TIMESTAMP, CURRENT_TIMESTAMP, "
"NULL, 'NO', NULL)");
}
在初始化和启动时,会使用Object_table_definition_impl::get_ddl()函数来获取m_target_def中信息所生成的DDL语句,创建出schemata表;使用Object_table_definition_impl::get_dml()获取DML语句,用于初始化表中的数据。
dd::tables::Schemata类的继承关系,如图3。所有的数据字典表对应的类,最终都是派生自dd::Object_table,便于统一处理。
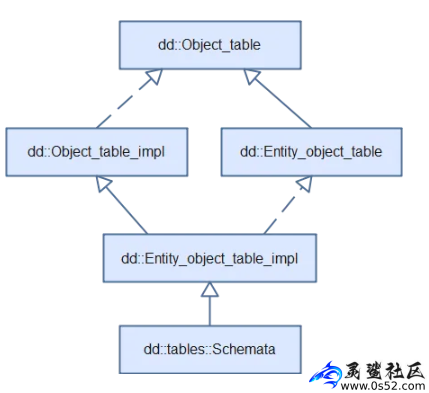
图3 dd::tables::Schemata类
对于这些表中存储的元数据所对应的对象,或者说这些表中的每一行数据所对应的一个对象,比如一个schema、table、column等,代码中也有对应的类。
还是以schema为例,它对应的类是dd::Schema,实现类是dd::Schema_impl,代表的是schema这种数据库内部对象,也是mysql.schemata表中的一行。
所有数据字典中所存储的对象在代码中的基类都是dd::Weak_object,如图4:
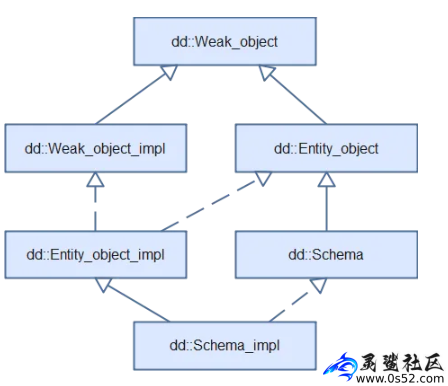
图4 dd::Schema_impl类
schema的id和name在dd::Entity_object_impl中,其他字段在实现类dd::Schema_impl中。
实现类dd::Schema_impl主要实现了对于元数据对象的各属性的读写访问,与从数据字典中的元数据表schemata的行记录中,存取元数据的接口。
主要相关接口如下:
arduino
class Weak_object_impl_ : virtual public Weak_object {
// ...
public:
// 存储记录到元数据表
virtual bool store(Open_dictionary_tables_ctx *otx);
// 删除元数据表中的记录 bool drop(Open_dictionary_tables_ctx *otx) const;
public:
// 从元数据表的记录中提取各属性字段
virtual bool restore_attributes(const Raw_record &r) = 0;
// 保存各属性到元数据表的记录
virtual bool store_attributes(Raw_record *r) = 0;
// 读取相关对象的信息,如表上的索引等
virtual bool restore_children(Open_dictionary_tables_ctx *) { return false; }
// 存储相关对象的信息
virtual bool store_children(Open_dictionary_tables_ctx *) { return false; }
// 删除相关对象的信息
virtual bool drop_children(Open_dictionary_tables_ctx *) const {
return false;
}
};
dd::Schema_impl主要实现了store_attributes和restore_attributes接口,依据dd::tables::Schemata中的表定义信息,读取或存储schema的各个属性信息。
依据以上介绍的,数据字典表的类与数据库内部对象的类,结合InnoDB存储引擎的接口,实现了对于存储于数据字典各个表中的元数据的读写访问。
例如,存储新建的database的元数据到schema内存对象中:
less
#0 dd::Schema_impl::store_attributes
#1 in dd::Weak_object_impl::store
#2 in dd::cache::Storage_adapter::store<dd::Schema>
#3 in dd::cache::Dictionary_client::store<dd::Schema>
#4 in dd::create_schema
#5 in mysql_create_db
#6 in mysql_execute_command...
持久化到对应的InnoDB表mysql.schemata中:
less
#0 ha_innobase::write_row
#1 in handler::ha_write_row
#2 in dd::Raw_new_record::insert
#3 in dd::Weak_object_impl::store
#4 in dd::cache::Storage_adapter::store<dd::Schema>
#5 in dd::cache::Dictionary_client::store<dd::Schema>
#6 in dd::create_schema
#7 in mysql_create_db
#8 in mysql_execute_command
...
数据字典的初始化
初始化MySQL数据库实例时,即执行mysqld -initialize时,main函数会启动一个bootstrap线程来进行数据字典的初始化,并等待其完成。
数据字典的初始化函数入口是dd::bootstrap::initialize,主要流程如下:
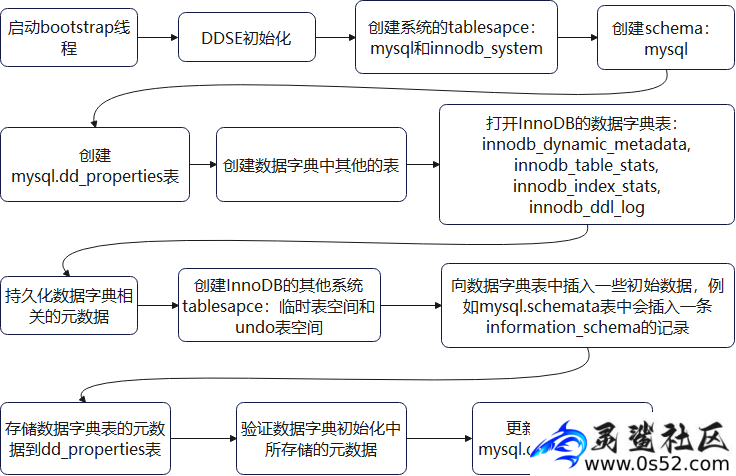
图5 数据字典初始化流程
其中,DDSE指的是Data Dictionary Storage Engine,数据字典的存储引擎,即InnoDB。DDSE初始化过程主要是对InnoDB进行必要的初始化,并获取DDSE代码中预先定义好的表的定义与表空间的定义。
InnoDB预定义的数据字典表:
- innodb_dynamic_metadata
InnoDB的动态元数据,包括表的自增列值等。
- innodb_table_stats
InnoDB表的统计信息。
- innodb_index_stats
InnoDB索引的统计信息。
- innodb_ddl_log
存储InnoDB的DDL日志,用于原子DDL的实现。
InnoDB预定义的系统表空间:
- mysql
数据字典的表空间,数据字典表都在这个表空间中。
- innodb_system
InnoDB的系统表空间,主要包含InnoDB的Change Buffer;如果不使用file-per-table或指定其他表空间,用户表也会创建在这个表空间中。
InnoDB的ddse_dict_init接口的实现为innobase_ddse_dict_init,会先调用innobase_init_files初始化所需文件并启动InnoDB。
主要代码流程如下:
rust
static bool innobase_ddse_dict_init(
dict_init_mode_t dict_init_mode, uint,
List<const dd::Object_table> *tables,List<const Plugin_tablespace> *tablespaces) {
// ...
// 初始化文件并启动InnoDB
if (innobase_init_files(dict_init_mode, tablespaces)) {
return true;
}
// innodb_dynamic_metadata表的定义
dd::Object_table *innodb_dynamic_metadata =
dd::Object_table::create_object_table();
innodb_dynamic_metadata->set_hidden(true);
dd::Object_table_definition *def =
innodb_dynamic_metadata->target_table_definition();
def->set_table_name("innodb_dynamic_metadata");
def->add_field(0, "table_id", "table_id BIGINT UNSIGNED NOT NULL");
def->add_field(1, "version", "version BIGINT UNSIGNED NOT NULL");
def->add_field(2, "metadata", "metadata BLOB NOT NULL");
def->add_index(0, "index_pk", "PRIMARY KEY (table_id)");
// ...
/* innodb_table_stats、innodb_index_stats、innodb_ddl_log表的定义 */
// ...
}
在DDSE初始化并启动的基础上,就可以进行剩下的数据字典初始化过程,主要就是创建数据字典的schema和表。这些表的元数据在执行flush_meta_data时进行持久化。
值得注意的是表mysql.dd_properties,它会存储版本信息等数据字典的属性,还会存储其他数据字典表的定义、id、se_private_data等信息,在数据库启动时使用。
数据字典初始化整体执行的函数调用总结,如图6:

图6 数据字典初始化的函数调用
数据字典的启动
数据字典的启动过程所执行的函数与初始化时十分相似,大部分在函数内部通过opt_initialize全局变量来区分初始化和启动,执行不同的代码逻辑。
与初始化的主要区别是元数据不再需要生成并持久化到存储,而是从存储读取已有的元数据。InnoDB文件是打开已有的,而不是新建。
数据字典启动的入口是dd::upgrade_57::do_pre_checks_and_initialize_dd。这里虽然有'upgrade_57'这种名称的namespace,但是正常的启动也是从这里开始。
与初始化相同,数据字典的启动也是先准备好DDSE,即启动InnoDB,然后再进行后面启动数据字典的步骤。打开数据字典之前,InnoDB会进行数据字典的恢复,确保重启前的DDL都正常的提交或回滚,数据字典元数据和数据是处于一致的状态。
dd::upgrade_57::restart_dictionary调用dd::bootstrap::restart,后面的启动步骤由它来实现,主要过程如下。
注意这里的创建表,是创建内存中的对象,不是物理上新创建一个表。这些表的元数据都已经在初始化时持久化了。
scss
bool restart(THD *thd) {
bootstrap::DD_bootstrap_ctx::instance().set_stage(bootstrap::Stage::STARTED);
// 获取预定义的系统tablespace的元数据(mysql和innodb_system)
store_predefined_tablespace_metadata(thd);
if (create_dd_schema(thd) || // 创建schema:'mysql'
initialize_dd_properties(thd) || // 创建mysql.dd_properties表并从中获取版本号等信息
create_tables(thd, nullptr) || // 创建数据字典中其他的表
sync_meta_data(thd) || // 从存储读取数据字典相关的schema、tablespace和表的元数据,进行同步
/* 打开InnoDB的数据字典表(innodb_dynamic_metadata, innodb_table_stats, innodb_index_stats,
innodb_ddl_log),加载所有InnoDB的表空间 */
DDSE_dict_recover(thd, DICT_RECOVERY_RESTART_SERVER,
d->get_actual_dd_version(thd)) ||
upgrade::do_server_upgrade_checks(thd) || // 检查是否能够升级(如果需要的话,正常启动不涉及)
upgrade::upgrade_tables(thd) || // 升级数据字典表的定义及其中的元数据(如果需要的话,正常启动不涉及)
repopulate_charsets_and_collations(thd) || // 更新charset和collation信息
verify_contents(thd) || // 验证数据字典内容
update_versions(thd, false)) { // 更新版本信息到dd_properties表
return true;
}
// ...
bootstrap::DD_bootstrap_ctx::instance().set_stage(bootstrap::Stage::FINISHED);
LogErr(INFORMATION_LEVEL, ER_DD_VERSION_FOUND, d->get_actual_dd_version(thd));
return false;
}
启动时各个数据字典表的根页面信息是从 mysql.dd_properties表中获取的,通过该页面可以访问对应表的所有数据。
mysql.dd_properties表的根页面是固定的,并且它里面保存了数组字典表本身的元数据。相关函数:dd::get_se_private_data()。
小结
MySQL 8.0新设计实现的数据字典,解决了之前版本的数据字典冗余,DDL原子性、crash safe等问题。通过对数据字典的初始化流程,以及数据字典正常重启时加载流程的梳理,希望读者对新数据字典的实现和运行有一个更深入的了解。
评论